Убедитесь, что в вашем рабочем проекте в конечном итоге создаётся физическая система, а не просто какое-то описание. Что изменится в физическом мире, если ваш проект закрыть прямо сейчас, чего в физическом мире не будет существовать без результатов вашего проекта? Что делает ваша система в физическом мире, какой процесс она в нём осуществляет, какая «непоправимая польза» наносится миру этим его изменением со стороны вашей системы? Чего не будет хорошего, если ваша система не будет осуществлять этого поведения?
А в ШСМ знают толк в сложных и заставляющих сильно задуматься вопросах. Попробую формулировать по порядку.
Если выключить сервера Planfix — то собственно в первом приближении в физическом мире перестанут существовать базы данных и программы манипуляций над ними. Но смысл — не в работе эти баз данных и программ самих по себе. Поэтому дальше по цепочке — ими не смогут пользоваться наши клиенты, для них исчезнет их экзокортекс — внешнее хранилище информации о работах / клиентах / заказах. Кроме того, для них будут нарушены каналы коммуникаций между сотрудниками, а также с их собственными клиентами. Можно ли считать средство обеспечения электронной коммуникации существующим в физическом мире? По моему мнению да, передача электронных сообщений — это если опускаться на самые низкие уровни — изменения конкретных молекул. Если из всей цепочки обеспечивающей такую коммуникацию (компьютер клиента, сеть интернета до датацентра, софт работающий в этом датацентре и так далее до второй стороны коммуникации) мы вынимаем софт — мы физически нарушаем конкретно этот канал коммуникации.
О, после ответа на первый вопрос, можно из него вывести ответы и на следующие два — хотя я не могу сказать, что я ими доволен. Обеспечение функционирования экзокортекса и коммуникаций. Недоволен — потому что формулировка получилась заумная. Без экзокортекса можно работать — на бумажке например, софт лучше бумажки тем, что даёт дополнительные возможности: простоту поиска, упорядочивание данных, напоминания и другое. Тогда непоправимая польза нашего продукта — это вот это улучшение, но физично ли оно? Тут надо ещё думать. С коммуникациями кажется чуть проще. Чем planfix лучше условного рабочего чата в телеграме — возможностью одновременно общаться по разным рабочим вопросам, не смешивая их и отдельно отслеживая состояние каждого. Натягивая предыдущее рассуждение о физичности канала коммуникации — можно сказать, что мы предоставляем многоканальную коммуникацию с дополнительными удобствами.
Ответ получился неидеальный и явно есть еще куда думать — и какую ещё пользу мы приносим кроме экзокортекса и коммуникаций, и как по-другому выразить мысль про экзокортекс.
У меня есть традиция — раз в пару лет я перепрохожу курс Системного мышления в ШСМ. Потому что раз в пару лет он переписывается и обновляется и при новом прочтении появляются новые мысли (да и он слишком плотный по информации, чтобы всё полноценно осмыслить и внедрить в свои практики в один заход).
С неделю назад начал активный заход номер три и пока прочел только обновленную первую главу, которая скорее введение, общие размышления и т.п.
Что больше всего зацепило в ней — это глава о метанойе. Не помню была ли она в предыдущих версиях, может и была, но не оставила следа, так как мозг переваривал другие идеи — о важности и неважности терминологии, например, а сейчас они уже усвоены и читались в формате «да, да, да, а как же иначе». Но возвращаясь к метанойе — это свойство прохождения некоего порога понимания. До его прохождения — идеи кажутся странными / непонятными и тяжело принимаются, после — непонятно, почему раньше они не были очевидными.
И главное в этом то, что пока ты прошёл этот порог — ты не можешь двигаться к чему-то за ним. В программировании — подобным «рубежом» служат, например, указатели, асинхронные вызовы, понимание обработки информации, как трансформирования потоков данных — они требуют именно какого-то поворота в мозгах. И подобные рубежи есть во многих отраслях. И именно явление метанойи даёт ответ чем вузовское образование превосходит самообучение — наличие разработанной программы обучения позволяет плавно подойти и перейти этот порог, а не пытаться с наскока постичь концепты за ним, которые просто никак не могут быть полноценно поняты и уложены в мозгу.
Под «вузовским образованием» я понимаю тут любое образование с хорошо проработанной программой в противовес распространенному сейчас сочетанию видео на ютубе + чтение статей.
Книга о том, как гугл обеспечивает надежную работу своих систем, а также эволюции подходов к надежности.
В целом — очень полезно и хорошо, но надо понимать, что это не цельная книга, а скорее сборник эссе разных авторов. Из-за чего в ней намешано сразу всё:
как устроены датацентры гугла
общие принципы работы SRE в гугле
процессы инцидент-менеджмента
процессы найма и онбординга SRE-инженеров
технические вопросы — типа как гугл обеспечивает шардирование данных или борется с повышенной нагрузкой и др.
Из всего этого на текущий момет мне наиболее полезными показались главы именно про организацию процессов. Технические главы — часто или слишком привязаны к гуглу, или стоит внимательно читать, когда возникнут такие же проблемы — местами там было многовато конкретики и меньше общих принципов.
Особенно полезными показались главы
Про инцидент менеджмент как процесс. Работа над инцидентом не должна быть авралом. В Гугле есть отлаженный процесс работы над инцидентом, в которых участвует несколько человек, каждый из которых играет свою роль. В частности отдельные люди занимаются коммуникациями с внешними командами и если необходимо пользователями. Построен процесс передачи данных между сменами инженеров, если инцидент длится долго. В процесс вплетен сбор данных для последующего постмортема.
Про написание постмортемов — полезная практика, но сразу надо понимать, что занимает значительное время. Желательно чтобы заранее было определено какие ситуации требуют их написания и было явно выделено время на их написание — без этого ничего не полетит.
Про главный принцип работы SRE — что SRE должны не менее 50% времени тратить на разработку — автоматизацию, улучшение инфраструктуры и т.п, а не на повторяюшиеся ручные операции и тушение пожаров. Если этого не делать — всё скатывается к тому, что рост системы требует постоянного увеличение числа инженеров — а их найм и обучение очень сложны.
Про бэкап данных. Важная мысль — результат работы в этом направлении — не бэкап, а успешное восстановление. Нет смысла делать бэкап, не подумав, как и за какое время мы будем из него восстанавливаться и отвечает ли это нашим требованиям.
Ну и общий главный принцип подхода к работе:
Unlike almost everything in life «boring» is actually a positive attribute when it comes to software. We don’t want our programs to be spontaneous and interesting. We want them to predictably accomplish business goals
В целом 20+ часов на прослушивание были потрачены не зря 🙂
Книга о росте менеджера в IT от ментора стажёров до CTO. Мне очень понравилась, в первую очередь тем, что речь не о абстрактном менеджменте или менеджменте заводов и отделов продаж — а именно о нашей отрасли, понятными примерами из неё.
Дальше отдельные заметки, из того что понаотмечал себе (и там скорее то, чего сейчас у меня нет / не хватает на это времени / не понятно нужно ли оно).
Про 1-on-1 — регулярность и формальность, чтобы :
на них находилось время
находилось время на что-то кроме них
т.е. чтобы можно было организовать отрезки времени, когда тебя не отвлекают
При этом при небольшой команде и плотной работе с ней — надо понимать, зачем они и что там обсуждать, нет смысла превращать это в дублирование статус репортов.
Про план развития и план на 30-60-90 дней. Второе — хорошая штука при онбординге. Первое может быть нужно в первые n лет. Хорошей практикой должно быть требование роста. Т.е. если работник не вырос за год-два-три — это повод с ним расстаться. Хорошие примеры про отмазки и причины почему задачи брались медленнее и вообще роста не получалось — тут был праздник, а тут вы были в отпуске, а тут у меня болела собака — все по отдельности, ок, но когда оно сплошняком — повод задуматься.
Про грейды — взять чьи-то чужие грейды — прямой путь к фейлу. Если мы вводим их в первый раз — лучше делать их на основе сложившихся уже уровней в вашей компании. Задуматься о них стоит, если ушло 2-3 человека, потому что им не понятны карьерные перспективы. Раньше скорее всего — лишняя трата времени и лишняя бюрократия. Если и вводить грейды, то в зависимости от ответственности (а не знаний или навыков), широкие и с пересекающимися вилками, если они привязаны к зарплате.
Про построение процессов — рост формальности процессов растет с ростом компании, по мере роста рисков и из-за удаления руководителя разработки от непосредственно кода, для того, чтобы не было внезапных сюрпризов. Может происходить как проактивно (но надо не перестараться и не бездумно внедрять все подряд, а понимать, какие риски мы сейчас покрываем конкретно этой практикой), так и реактивно по мере инцидентов (классный пример, что ааа, тут второй месяц пишут непойми что и прогресс неясен, а там новая функциональность оказалась написана на скале, которую в компании не знает никто, кроме того, кто это написал, и на это потрачено уже достаточно много времени, чтобы просто от этого теперь отказаться). Мысль, что код ревью — не ловит баги, баги ловят тесты, а социальная практика, повышающая качество кода за счет знания, что кто-то его будет смотреть (и увидит, что он на скале :), и насмотренность на разные части продукта разными разработчиками
Книга не новая, 2011 года, поэтому не могу сказать, что содержит какие-то прям прорывные идеи — все эти идеи я уже много раз слышал в других статьях, книгах и т.п. Однако читать первоисточники все рано полезно — с одной стороны даже услышав заново уже знакомую мысль, обдумываешь ее заново, применительно к текущей ситуации в своих проектах. С другой, не в первый раз убеждаюсь, что краткие пересказы и упоминания идей не вызывают такого отклика, как та же идея, но более подробно расписанная и подкрепленная примерами у автора.
Итак, какие основные идеи содержит эта книга.
Во-первых измеряемые изменения и ускорение цикла Build — Measure — Learn. Автор советует доходить вплоть до возведения этого принципа в абсолют — не планировать никакие изменения, если не решено как будет измеряться и оцениваться их результат. На бумаге или для нового продукта звучит хорошо — на практике же всё сильно сложнее, померить эффект от изменения дизайна на «более современный» к примеру практически невозможно. Но держать эту мысль в голове и каждый раз думать можно ли ее применить — это хорошая мысль. Интересно, что в эпилоге автор отсылает к прочитанным мной недавно «Принципам научного менеджмента» Тейлора — называя себя с одной стороны продолжателем принципов Тейлора, но с другой пытаясь отдалить себя от них, отмечая, что принципы применяем не к работоспособности конкретного человека и выжиманию максимума из него, а к работе организации в целом, построении организации как системы.
Вторая, наверно самая известная идея из этой книги — MVP, максимально быстрый выпуск минимального продукта, с целью получения обратной связи. Про это после этой книги написано столько, что сейчас это скорее звучит как повторение общепринятых истин.
Третье, чему в книге посвящено много времени — это идея пивота. Тут было очень полезно послушать. Особенно мысль, что пивот — это не показатель фейла продукта (хотя иногда это и так). Даже у успешного и относительно успешного продукта пивот может быть необходимой стадией развития на этапе перехода от продукта для early adopters к более массовому продукту. Причем пивот может заключаться не обязательно в изменении самой сути продукта — выход на другие географические рынки это тоже пивот, так как требует изменений в работе над продуктом и смены приоритетов. Кроме того меняется не только сам продукт, но и мир вокруг него, поэтому даже для успешного продукта надо следить за этим и не прозевать необходимость серьезных изменений. Но при этом самое сложное — понять, нужно ли уже думать о пивоте или надо продолжать прикладывать усилия в текущем направлении и успех возможен и без пивота, но нужно сильнее развить продукт, сделать всего больше, лучше и т.п.
Следующая идея — это организация работы в small batches. Сильно пересекается с ускорением build-measure-learn и собственно необходимо для этого ускорения, да и для MVP также. Кроме самой идеи тут особо ничего про это не было, а идея не новая.
Ну и рассуждения про необходимость найти модель роста, упоминания юнит-эономики, виральности и вот этого всего — но опять таки только упоминания и по верхам
В целом было полезно, но в 23м году ближе к Демингу и Тейлору — т.е. как первоисточник идей, на которые все ссылаются. (судя по популярности книги, в 2011 году они видимо были не настолько мейнстримом и возможно тогда звучали как что-то новое)
Внезапно очень хорошая книга. Внезапно, потому что в названии книги явно говорится, что она про построение микросервисов, хотя на самом деле она скорее о построении программных продуктов разного размера и о том, какие трансформации необходимы в том случае, если мы хотим, чтобы над одним продуктом могли эффективно работать большое количество людей.
При этом значительное число предлагаемых практик, советов и рассуждений полезны и для компаний нашего размера, где микросервисы были бы только вредны (в том числе советы не использовать то-то и не лезть туда-то, если вы маленькие и у вас нет проблем, для решения которых это то-то и туда-то придуманы)
Автор начинает с рассуждений зачем вообще нужны микросервисы и какие альтернативы им есть — монолит, модульный монолит, распределенный монолит. И сразу выделяет главное, для чего в принципе нужны микросервисы — возможность независимого развития и деплоя. Если у вас много команд и необходимо, чтобы отдельные команды могли независимо развивать свою часть продукта и независимо его деплоить, уменьшая вероятность сломать и задеть прочие части продукта — то микросервисы вам вероятно нужны. Если команд у вас мало и вы маленькие — надо обязательно оценивать повышенные расходы на поддержание микросервисов — как инфраструктурные, так и организационные и когнитивные — и думать, перевешивают ли они ожидаемые бонусы.
Автор не скупится на описание минусов микросервисов (тем более что потом всю книгу будет описывать в основном плюсы): — С ними сложнее работать разработчикам — развернуть локально систему из большого числа микросервисов практически невозможно — Поэтому же микросервисы гораздо сложнее тестировать, особенно когда речь идет о end to end тестах — Инфраструктурно — это всегда бо‘льшие затраты — Мониторинг — усложняется в разы, как и вообще понимание того, насколько хорошо работает сейчас наша система — При каких-то поломках поиск причин может быть крайне сложным — Latency — физика беспощадна, сетевые вызовы всегда дороже, если один вызов пользователя проходит через множество сервисов — он может быть нестерпимо медленным — Data consistency — если у каждого сервиса своя БД — то какая из них источник правды?
После этого автор переходит к описанию как строить микросервисы и рассматривает следующие моменты (отмечаю не всё, т.к. книга длииннная и там много всего, а только то, что показалось полезным, очередной рассказ по верхам про саги например — не очень): — Как проектировать микросервисы — очень много отсылок к DDD — и в принципе краткое изложение идей оттуда — Как распиливать монолит — основные идеи и отсылки к книге Monolith to microservices (она у меня как раз лежит в списке на чтение) — сами идеи уже много где встречал, но тут они хорошо собраны рядом. — Паттерны общения между сервисами — синхронное, асинхронное и через общие данные. Тут была очень важная мысль, что общая БД — это в том числе способ общения, очень асинхронный — и поэтому и возможное место место взаимозависимости. — Как производить изменения взаимосвязанных микросервисов — некоторые моменты зависят от используемых технологий, но многие идеи общие — про максимальное сохранение обратной совместимости и по возможности постепенное изменение, вместо breaking changes. Важный момент — не забывать про человеческую часть изменений — в процесс изменений должно быть заложено информирование всех, на кого оно влияет, а также согласование скорости изменений и их необходимости. — Тестирование. Автор бегло проходит по пирамиде тестирование и с сожалением отмечает, что e2e тесты писать становится очень сложно. Иногда до невозможности. Чтобы как-то компенсировать это предлагает использовать тесты на контракты ну и тестирование в проде. — А чтобы тестировать в проде — нужна повышенная observability. Тут глава была очень полезная, т.к. observability нужно всем — не только микросервисам. Основная идея проста — необходимо построить набор инструментов и сбора статистики, который бы позволял понимать, что сейчас происходит в системе. Для этого никак не обойтись без агрегации логов, агрегации метрик и желательно чтобы их формат и состав был стандартизирован между всеми микросервисами. — Дальше опять идет про то, где микросервисы делают жизнь скорее сложнее — безопасность (упоминается концепция Zero Trust) и стабильность. Да, с одной стороны микросервисы позволяют сделать так, чтобы изменение в маловажной области не свалило всё приложение, но с другой — X сервисов — это X мест, где что-то может пойти не так (особенно вспоминая про нестабильную сеть) и всё общение между сервисами должно предусматривать возможность проблем / таймаутов и т.п. с другой стороны.
Последняя глава посвящена тому ради чего вообще делают микросервисы — людям. Организации работы большого количества команд. Упоминается много идей из Team Topology (видимо одна из тех книг, которую я еще не читал, но ее так часть упоминают, что есть ощущение, что все основные идеи из нее уже слышал). В частности stream-aligned teams, enabling teams, platform teams.
В целом — очень много информации, ничего особенно революционного и нового, но хорошо собрано и скомпоновано всё вместе, с отсылками на другие книги, где отдельные вопросы рассматриваются подробнее.
Книга не новая, первое издание вышло еще в 1993 году (в том же году умер автор), но так как Дёминг считается одним из классиков теории менеджмента — было весьма интересно прослушать. Что интересно — книга вполне актуальна, и не знай я, что она написана в 1993 году мог бы подумать, что она современна, Дёминг как будто спорит со многими статьями в интернете и обсуждениями в телеграм-чатах 🙂
В первую очередь и затем многократно на всём протяжении книги Дёминг говорит о вреде конкуренции (внезапно 🙂
Когда мы говорим о конкуренции между предприятиями, то по мнению Дёминга, чем бороться за передел рынка — стоит тратить усилия на его расширение. Он приводит в пример ситуацию в автомобильной отрасли, когда пока американские производители делили рынок — на него пришли японские производители предложившие более бюджетные автомобили и забравшие значительную долю рынка, которой до их прихода не существовало.
Но ещё подробнее Дёминг пишет о вреде конкуренции внутри одного предприятия. Все отделы и работники фирмы должны работать на общее благо, величайшей ошибкой менеджмента является ситуация, когда отдельный отдел или менеджер может извлечь ситуативную выгоду для себя или отдела, которая вредит фирме в целом. Дёминг приводит понятные примеры — например, когда отдел закупок снижает затраты, закупая худшие по качеству материалы, выписывая себе в достижение снижение расходов — притом, что это приводит к увеличению брака, увеличению расходов на производство, снижению качества продукции и в итоге общему снижению доходов предприятия.
Но зачем они делают так — виной тому плохие люди и работники? Нет, по мнению Дёминга виной тому плохой менеджмент, внедривший систему KPI. Многократно и с разными примерами он говорит о вреде любых числовых KPI, где бы то ни было — на производстве, в обучении и так далее. Их внедрение приводит к тому, что цели фирмы заменяются целями достижения неких отдельных цифровых показателей в ущерб общему делу.
Вместо этого все менеджеры должны иметь глубинное понимание всей системы — всего процесса производства от начала и до поставки результата клиентам. А для улучшения качества и уменьшения расходов на производстве — вместо придумывания числовых KPI и гонки за ним — использовать систему постоянного улучшения процесса.
Чтобы добиться постоянного улучшения важно понимать вариабельность систем — отличать, какие отклонения являются нормальными для текущего процесса, а какие — случайные и мимолетные вмешательства. Необходимо для начала максимально насколько это возможно «стабилизировать» систему — уменьшить вариабельность выдаваемого ей результата, а потом улучшать процесс в целом.
Если в этом не разбираться и этого не делать, то для примера, в случае с таким распространенным мотивационным инструментом как премии за результат — мы можем получить ситуацию, что премии выдаются на основе случайных отклонений или отклонений, заложенных в сам процесс, индивидуальное воздействие на которые крайне мало. И в таком случае они не то, что не способствуют улучшению, а наоборот вредят — демотивируя людей.
Для иллюстрации этой идеи Дёминг описывает эксперимент с красными бусами — он весьма показателен — так что я нашёл ссылку именно на его описание 🙂 https://advanced-quality-tools.ru/deming-redbeadexperiment.html
Отдельно отмечу некоторый минус конкретно этого издания книги — где-то четверть если не больше — это не сама книга и мысли Дёминга — а предисловие и послесловие о том, как Дёминг велик, как он крут и как все должны к нему прислушаться 🙂 Оно весьма вероятно так — но меня бы больше устроило, если бы этот контент занимал процентов 5 🙂
Авторы начинают со стандартного блаблабла о важности архитектуры, о работе архитектора и т.п. Там в целом в книге много такого, так что я буду обозначать только те моменты, которые мне показались полезными, пропуская то, что не очень 🙂
Первой полезной главной внезапно оказалась глава о модульности. Казалось бы, ну что ещё можно сказать о модулях, связности и т.п. думал я — но оказалось, что учиться и узнавать новое никогда не поздно 🙂 После рассказа про то, что такое модульность, авторы переходят в характеристикам определяющим степень связности внутри ПО. Начинают с coupling (тут было все знакомо), но затем переходят к непроизносимым (и с неугадываемым на слух написанием) cohesion и сonnascence.
Cohesion — в отличие от coupling, показывающей степень зависимости модулей между собой — показывает степень взаимосвязи функций внутри модуля и может служить показателем того, не нужно ли разделить модуль на несколько.
Connascence — это более точная характеристика взаимозависимости, она возникает между двумя модулями, если изменения в одном требуют внесения изменений в другой, чтобы система в целом оставалась корректной. Она бывает разной степени — от простой зависимости от имени или типа, до более сложных зависимостей — от смысловых значений констант, от времени и порядка выполнения и др
Дальше авторы переходят к рассуждениям о том какие бывают архитектурные характеристики и о fitness functions для них. Материал сильно совпадает с книгой Building evolutionary architectures. Из нового (или упущенного мной при чтении той книги) — мысль о роли фитнес функций как инструмента управления (governance), когда архитектор непосредственно не пишет и не ревьюит код, но обеспечивает нужные характеристики через фитнес функции.
От самих характеристик разговор переходит на то, являются ли они характеристиками всей системы? Вводится понятие архитектурного квантума — части системы, которая обладает отличными от других частей НФТ. Тут мне показалось в книге присутствовал перекос в сторону — подумайте каким частями системы какие НФТ нужны и таким образом разбейте ее на разные квантумы, вместо — подумайте? правда ли разным частям вашей системы нужны разные НФТ, что потребует разбить ее на разные квантумы. Правильная мысль тут — если несколько выделенных вами квантумов используют одинаковый набор технологий и возможно даже общую бд — то точно ли итоговые НФТ у них получаются разные? Точно ли ваш код влияет на них настолько — если у вас супер scalable приложение, но при этом общая бд, без шардирования и возможностей кластеризации — уверены ли вы, что ваша система в целом scalable.
Следующей очень интересной главой была глава про компоненты, проектирование системы исходя из них. Не сказать, что что-то новое, но наводящее порядок в голове. Авторы пишут, что есть два основных подхода к выделению компонентов. Первый — исходя из технических характеристик (слоеная архитектура, mvc) — компонент работы с базой, компоненты бизнес логики, компоненты представления. Второй — исходя из бизнес-доменов, по заветам DDD. Оба имеют свои плюсы и минусы и какой выберете вы во многом должно зависеть от закона Конвея — как организованы люди у вас в компании. Если у вас отдельные отделы дба, бэкенда и фронтенда — вам ближе первый способ. Если же кроссфункциональные команды, отвечающие за отдельные части продукта — второй. Но верно и обратное, можно воспользоваться обратным законом Конвея и, если вы по каким-то причинам предпочитаете какой-то из этих подходов — надо переорганизовать команды, чтобы они соответствовали выбранной архитектуре.
Во второй части книги начинается описание архитектурных стилей. И начинается он просто огненно — упомянув, что базовым водоразделом между разными стилями является какая архитектура — монолитная или распределённая используется — авторы рассказывают о заблуждениях (fallacies), которые часто бывают при построении распределенных систем. Я просто перечислю их тут, а в книге к каждому заблуждению приводятся примеры и объяснения:
сеть надёжна
латенси равна 0 и ей можно пренебречь
сетевой канал бесконечно широк
сеть безопасна
топология сети и распределенных сервисов неизменна
существует только один администратор
транспортные расходы пренебрежимо малы
После чего, видимо чтобы добить слушателей упоминают ещё сложности с распределенными транзакциями и логированием
На этой оптимистичной ноте происходит переход к рассказу о разных архитектурах и для начала — о слоеной архитектуре. Ничего особо нового тут не говорится, разве что отмечу мысль об опасности скатиться к sink hole — когда промежуточные уровни в подобной архитектуре не делают ничего, а просто передают запросы дальше. Также интересная мысль, что с такой архитектуры часто начинают, так как она требует минимального продумывания на первом этапе и упрощает ориентирование в кодовой базе, пока она небольшая (как в зеркало гляжусь при чтении этого)
Далее авторы рассматривают
Рipeline architecture — интересный подход, тоже монолитный, но несколько снижающий сложность и повышающий независимость отдельных компонентов (если только вы не наворотите сложную сеть этих фильтров)
Microkernel architecture — система с общим ядром и подключаемыми плагинами. Теоретически может быть хороша , когда разные плагины могут по-разному менять или расширять проведение. На практике — в какой-то момент новые фичи требуют расширения не предусмотренного заранее — что влечёт необходимость изменения и общего кода и часто всех плагинов.
Service based architecture — первая распределённая архитектура. Авторы предлагают ее называть далее макросервисной — сервисы большие, продукт состоит из 6-20 сервисов. Чаще всего при этом используется одна БД. При использовании одной БД важное тут, чтобы сервисы не были связаны друг с другом структурой БД.
Event driven architecture — архитектура на основе обработки потока событий. Описывается два варианта топологии — broker и mediator. В первом случае есть только общая инфраструктура для передачи сообщений, логика определяется самими обработчиками событий, можно легко добавить новые обработчики, не предусмотренные ранее. Но очень сложно обрабатывать ошибки, очень сложно понять завершилась ли операция и успешно ли. Второй — с центральным медиатором, который управляет процессом и контролирует ошибки, завершение процесса и т.п. Также в этой главе описываются вопросы асинхронной обработки сообщений без потери данных, организации запроса-ответа в эту архитектуре, но подробнее эта тема рассматривается в недавно прочитанной Enterprise Integration Patterns. У нас события активно используются и в этой главе ничего особо нового для меня не было.
Space based architecture — очень интересная архитектура, в которой центральная БД заменяется распределенным реплицированным кешем, таким как hazelcast или apache ignite. Или если данных много или они очень часто обновляются — общим распределенным кешем. Плюс — высокая скорость работы, высокая доступность (в случае реплицированного кеша). Минус — высокая сложность, ограниченная применимость (далеко не все данные можно полностью поместить в оперативную память, ещё и дублируя ее на многих нодах). Но интересно.
Затем авторы проходятся по orchestration driven service based architecture — как примеру того, что осталось в прошлом, хотя было нацелено на казалось бы благородную цель — максимальный reuse кода и компонентов. В итоге это на практике выливалось в очень сильную связность и сложность внесения изменений, так как от одних компонентов зависит множество других.
И наконец приходят, как к ее противоположности, к микросервисной архитектуре. Честно говоря в главе про нее ничего особо нового не говорится — мысли те же, про связанность ее с идеями DDD и bounded contexts. Важный момент про необходимость избегать распределенных транзакций и что их наличие в большинстве случаев говорит о том, что сервисы выделены неверно — или слишком мелко или не по тем границам — всё требующее транзакции, за очень редкими исключениями, должно быть внутри одного сервиса.
Как выбрать архитектурный стиль из описанных — it depends — от приложения, требований, команды и т.п.
Последняя часть книги посвящена не архитектуре самой по себе, но работе архитектора:
как документировать и описывать архитектуру — тут описывается идея ADR. Мне показалось что оно должно быть хорошо применимо для больших команд, хотя возможно что какие-то важные моменты было бы неплохо так документировать и у нас (где только время на это взять)
анализ рисков, предлагается оценивать риски по метрике, характеризующей расположение риска на шкалах критичности и вероятности. Важная мысль — любая новая, неизвестная технология — это всегда high risk
насколько архитектор должен быть включен в работу команд, как найти правильный баланс на шкале control freak — armchair architect
базовые техники переговоров — основная мысль тут, что архитектурные решения надо не спускать сверху, а продавать разработчикам, объясняя зачем они приняты и по возможности давая разработчикам достаточно информации, чтобы они сами пришли к тому решению, которое считает правильным архитектор
Книга о том, как техническому руководителю говорить с бизнесом, так чтобы бизнес его понимал, а он понимал бизнес. Или 100500 вариантов квадрантов на все случаи жизни 🙂
В первой части автор рассматривает паттерны для анализа, на которые по его словам опираются все остальные. MECE lists, logic tree, hypothesis. Собственно интересное из этого только первое, да и то больше из-за названия, которое раньше не слышал — речь про списки непересекающихся сущностей, покрывающих при этом всё пространство возможных вариантов. В остальном в этой части много хороших рассуждений, но уж совсем базовых. В частности советы о договориться о терминах, но после Эванса оно воспринимается как — ну а как иначе-то.
Далее автор описывает паттерны анализа контекста окружающего мира, влияющего на вашу стратегию. Начинает с PESTEL — опять незнакомое мне ранее слово — суть, что надо посмотреть на влияющие на вас текущие изменения в области политики, экономики, общества (society), технологий, окружающей среды (environment) и законодательства (legal)
И далее, опираясь уже на них, делать сначала scenario planning — набрасывая вероятные сценарии, затем futures funnel, классифицируя различные вероятные сценарии будущего, выделяя среди них с одной стороны более вероятные, а с другой более желательные нам. Ну и далее применять backcasting, рассуждая какие предыдущие шаги необходимы чтобы попасть именно в желаемое нами будущее.
Следующими идут паттерны для анализа industry context
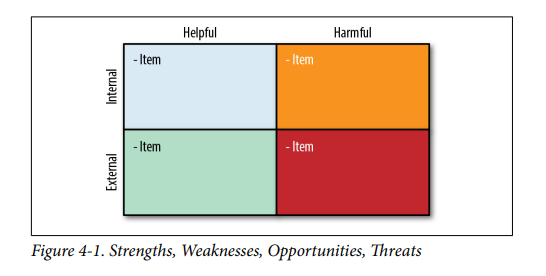
SWOT pattern
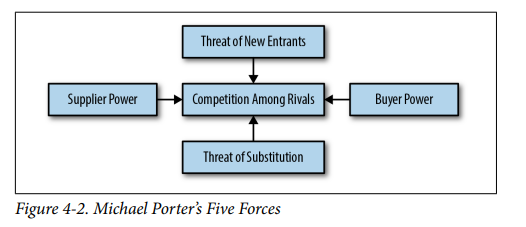
Porter’s Five Forces
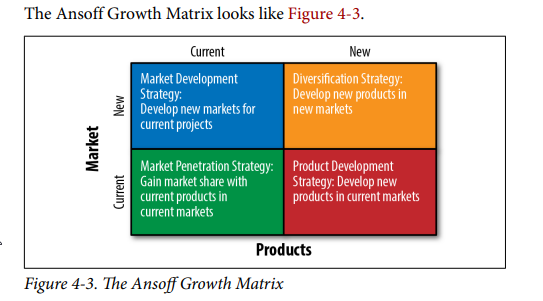
Ansoff Growth Matrix
По большому счету представляют собой паттерны «о чем подумать» относительно нашего продукта и его положения относительно конкурентов и возможного развития. Наиболее интересным тут показался именно SWOT, наверно потому он и наиболее на слуху.
Глава про Corporate context показалась не сильно интересной, потому что относится именно к работе в большой корпорации — все эти выясните стейкхолдеров, выясните откуда деньги, спланируйте запросы бюджета на проект весной, чтобы к следующему году этот бюджет получить… Ну и опять квадранты и квадранты.
Principles, practices, tools — идея из следующей главы про department context. Суть в том, что чтобы быть уверенным что компания движется в правильном направлении, мы обозначаем набор принципов, которым мы следуем как компания, но не останавливаемся на этом — а для каждого принципа перечисляем набор используемых практик и инструментов, поддерживающих эту практику. Предполагается выражать это например с помощью диаграмм https://sankeymatic.com/ Идея очень перекликается с идеями из курса системного мышления Левенчука, что мы меняем состояние альф, используя практики, поддержанные технологией. И принципы в таком случае должны отражать характеристики тех изменений в реальном мире, которые мы хотим получить в ходе деятельности нашей команды.
Другая идея из этой главы — application portfolio management (APM) — идея, что все разрабатываемые приложения оцениваются с одной стороны по степени их полезности для бизнеса, а с другой — по стоимости их поддержки — на основе этого принимаются решения от каких стоит отказаться, на какие направить лучшие силы и т.п. Опять предлагается рисовать квадранты 🙂
Вторая часть книги посвящена коммуникациям — когда вы решили, что и как делать — как донести эту мысль до всех от кого зависит ее реализация. Начинает автор с базовых идей — формулировать ответы в виде кратких 30 секундных ответов, смотреть на ситуацию непредвзято как это делал бы внешний консультант. Затем проходится по основным типам логических ошибок и наконец рассуждает как правильно добиваться принятия своих идей. Организационно — составить список стейкхолдеров на которых они повлияют и постараться в личных встречах и переписках сначала заручиться поддержкой их насколько это возможно (или как минимум узнать их опасения). Затем — кратко рассказывает основы сторителлинга.
Потом автор рассказывает, как организовать Scalable business machine — но выходит весьма краткое и неполное перечисление элементов системной схемы проекта из курса системного мышления Левенчука (которая в свою очередь основана на OMG Essence). Прямо вот это всё — что делаем в физическом мире, кто делает, какие роли есть в проекте, для кого делаем, с помощью каких практик, при помощи каких технологий — другими словами и по верхам, но о том же.
И в завершение показывает шаблоны которые использовать для презентации своих идей. Такие как One-slider — выражаем наше видение и как мы планируем реализовать его на практике кратко в одном слайде подобной структуры
А также Use Case Map, Priority Map, Technology Radar, Ghost desk, Ask desk и другие
Мне пока эта часть показалась не сильно полезной, наверно потому что работаю не в корпорации, где все это бы пригодилось 🙂
В целом — было весьма полезно. Узнал много новых слов и аббревиатур, книгу должно быть хорошо будет использовать и в будущем, как справочник фреймворков для анализа и шаблонов для презентаций.
Книга достаточно часто упоминалась в позитивном ключе в разных подкастах и твиттере — как книга-вдохновение для внедрения девопс.
Что могу сказать — авторы явно очень вдохновлялись Целью Голдратта 🙂 Настолько, что даже явно упоминают ее неоднократно в книге. Так что если вы читали Цель — то это она, но про нашу индустрию.
Как и Цель — это производственный роман, описывающий идею — так что главное тут не персонажи, они весьма шаблонные, а идеи трансформации в работе IT. Книга состоит из трёх частей — в первой описывается как было, во второй как из этого выбрались, ну и в третьей — движение к новым вершинам ) И честно говоря самой увлекательной была первая. Все эти проблемы, происходящие одновременно и необходимость и выбираться из них и как-то менять работу к лучшему… Честно говоря, такое начало породило у меня завышенные ожидания — я думал, что авторы покажут, как в таком режиме герои смогут осуществить трансформацию процессов работы, ещё и без поддержки начальства. Но увы — в конце первой главы главный герой кладёт заявление на стол и дальше появляется deus ex machina — влиятельный наставник и член совета директоров внезапно влияет на СЕО, да так, что тот внезапно прозревает (с чего бы?), заявляет, что был не прав и даёт главному герою полный карт-бланш на изменения, одновременно ещё и устраивая какой-то сеанс психотерапии с рассказом о своих слабостях и проблемах (что это вообще было?..). Увы-увы. На этом какая-то интрига и накал спадают (лишь изредка делается попытка создать хоть видимость интриги с нависающими сроками и интригами от главы маркетинга, метящей в СЕО — но слабенькая). И дальше книга превращается сначала в иллюстрацию того, как понять что ИТ должно делать для бизнеса. Тут все прямо как в Technology strategy patterns, которую я как раз читаю параллельно — составить список стейкхолдеров, составить список их KPI, составить список какие действия или бездействия IT больше всего влияют на них, определить какие меры могут дать максимальное влияние на показатели составляющие KPI руководства — привязать и показать прямую связь действий ИТ команды с конкретными бизнес показателями. А затем следует иллюстрированный примерами перечень идей по девопс трансформации — тут на сегодняшний день тоже никаких откровений — автоматизация деплоя и тестирования, уменьшение батч сайза релизов, частые и автоматические релизы, определение и устранение узких мест, плотная работа с бизнес-заказчиками. С учётом того, что внедряется оно в книге в режиме «придумали — без проблем внедрили, получили огромный профит» — не увлекает, внедрение контроля над изменениями в первой части было увлекательнее 🙂
Но в целом потраченного времени на прочтение (а точнее прослушивание) не пожалел 🙂 Первая часть была вообще огонь 🔥 — начало второй разочаровало, а дальше в принципе как неплохая бизнес-книга.